
This is Stage 3 of our Chemical Data Migration best practices whitepaper. Learn how to plan your project and assess your data in Stage 1, make sure your data is clean and compliant with business rules in Stage 2, execute the de facto migration in Stage 3, and ensure adoption and long term success with post-migration validation and support in Stage 4.
Until now, we were focusing on those tasks and objectives that all data migration projects have in common. Project planning, data analysis, business rule development and legacy data curation are steps which cannot be skipped without risking the quality of the data and the project timeline. Once these steps have been completed; and the chemical structures, as well as their attached data, have been prepared for migration, the data still needs to be moved from the original data source(s) to its new destination. This process can be largely categorized as an extract, transform and load (ETL) process. As with most ETL processes, the migration of chemical data is no easy feat - in fact, it is often the most time consuming step of the entire project. An ETL process can be implemented in many different ways; to find the optimal process, the size and complexity of the data should be considered, along with the capabilities of the old and new data systems. As such, it is essential to construct an execution plan for data migration that addresses the following topics.
Timelines
While unforeseen events can derail project timelines, projects commonly get off schedule because proper planning was not done. For example, the time dedicated for internal preparation was not enough, requirements were not complete, and/or the level of data analysis was insufficient. The negative impact of inadequate planning often only becomes apparent during the actual data migration. Therefore, migration teams should make sure that enough time has been reserved for potential reiterations over phases of the project.
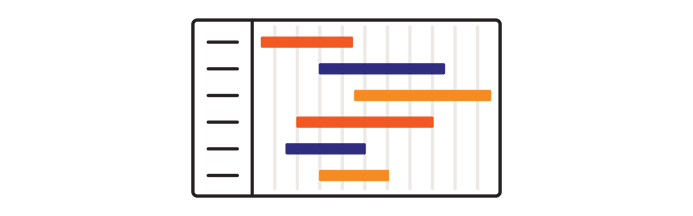
As was mentioned in the first part of the current whitepaper series, detailed project planning and management are important components of any successful migration project, and this includes planning a timeline in consideration of meeting all business requirements. The objective of the time planning phase is to give everyone an overview of the project and how resources are going to be managed. It requires a good understanding of all stakeholders and their availability during the entire project, and provides backup planning for those periods when stakeholders involved in the project will not be available.
To visualize project timelines with defined tasks, milestones, deliverables and dependencies, a Gantt chart is recommended, which is a useful graphical tool to follow project progress in any given point of time relative to the original deadline of each task.
Data sources
One of the first steps in a data migration plan should be to identify and understand the source of the legacy data. This includes the format and structure of the data, as well as any associated metadata or supporting documentation. Ideally, those sources should represent an organization’s entire compound library, which has already been validated and checked for data consistency, completeness, and accuracy in the aforementioned data curation step.
Preparing data for the physical migration also includes a step where the data has to be made available in a format which facilitates its transformation and loading. This might mean that the data is extracted into flat files first or a direct connection may have to be set up between the original data source and the new destination.
The two major approaches for chemical data migration are file export-import or direct data migration. These two methods are equally valid, and the decision will likely be guided by the vendors that you are migrating from/to and which options they support, as well as by the size and complexity of your data.
- File export-import
Exporting data from its legacy source to a file and then importing this file to the new environment is usually the most straightforward solution if the data set to migrate is relatively simple and has a small to medium size.
A common format for storing chemical structures and associated data is the structure-data file format (also called as SDF or SD file). SDFs are flat files that typically contain a collection of chemical structures in a specific format, along with metadata such as molecular weight, chemical formula, compound name etc. Due to the wide variety of supported chemistry features and the large number of applications recognizing it, SDF is one of the most frequently used formats to transfer chemical data between software systems. While there are other file formats comparable to SDF which can be used as an alternative (e.g., the MRV format from Chemaxon), using some of the simplified line notation based representations, such as SMILES, is not recommended. The reason for that is that the SMILES format does not support all chemistry features required to accurately describe chemical structures, including, for example, the enhanced stereo notation.
In addition to the chemical structure and its useful metadata, a file can also contain various data fields that are not relevant to the new database. Therefore, data mapping should be performed between the file’s fields and the columns of the new chemical database to ensure that only relevant data is transferred to the new database.
Besides being straightforward, file import-export also has the key advantage that it allows processing the data after export and before import. However, it might become cumbersome if you have to work with large (i.e., several hundreds of thousands or more compounds), complex data sets including different types of metadata and multiple hierarchical levels. In this case, direct data migration using a live database connection can be a more convenient solution.
- Direct data migration
Direct data transfer using a live connection between the source and the target databases is an alternative method for chemical data migration. This approach allows reading records directly from a source database, eliminating the need to extract the data from a flat file format. The connection can be established using various native database drivers, and the database administrator will need to provide the appropriate access via authentication credentials of some sort. This approach benefits from an unnecessary duplication of the data, but it requires a constant database connection through the entire migration process.
When directly migrating data between two databases, it is essential to understand the database schema, structure, and data types. Once the data model of the destination database has been determined, data mapping should also be performed - often with the help of data architects - to ensure that the data types and structures in the new database are compatible with the legacy data source. Mapping rules, along with the new model should be carefully documented during migration as a future reference material.
When using a direct database connection, it is also recommended to define a service user with all the necessary privileges to connect and execute data extraction and transformation. After connecting to the data source, it is important to confirm that all data can be accessed, metadata tables are well defined, and all additional information related to specific data structures are well described.
It is worth considering that direct data migrations can sometimes have limitations on the amount of data that can be extracted, which can impact the overall timeline of the migration project. Note that throughout the data migration, the original data source should be completely inaccessible by the end users to avoid any data inconsistencies between the source and destination. It can happen that a single-iteration migration is not possible; for example, because you have one very large data source or multiple different ones causing the migration process to take too long to keep the original source inaccessible. In such cases, the migration might be performed in one main iteration followed by smaller “top-ups”.
Data import
Many of the tasks mentioned so far, such as data assessment, business rule definition, data curation or data extraction and import file preparation, require a significant amount of manual work and regular contribution from various project team members. Thankfully, the next step - the importing of the data - is typically accomplished in an automated or programmatic fashion; however, it still requires monitoring and the occasional human intervention.
Automation of the data transfer is crucial for time efficiency; however, it requires Data Engineers or other IT Professionals to develop scripts or special applications to take care of data moving, monitoring and error handling. With these features it can be ensured that any interruptions during migration will be properly captured and logged and the data transfer can continue from the failing point in a timely manner. All missing records which have been identified and captured in the log files can then be migrated in the next iteration.
For the actual implementation of import scripts, several factors have to be considered. One of them is the technology and options the vendor you are migrating to supports. Depending on those options, one of the available vendor APIs might be used to import data in the new system, or direct database writing might be chosen as an alternative. Depending on the supported endpoints, data might be imported record-by-record or in bulk and error logging is implemented accordingly.
Another factor to consider is the complexity of the project and the migrated data landscape. For example, in case of very large data sets (with millions of records) coming from multiple sources, where migration can take several days, monitoring and error handling could be particularly important. In such cases, adding an intermediate step to the process could be considered, where the full legacy data set is transferred first into a “main stage table” (MST). The goal of the MST is to store original metadata, identifiers and structural data, and keep them as immutable data. After that, the main stage table can be used to perform any data processing and fixing steps, which have been detailed in the data curation part of this white paper series. With this approach the MST can be used to log all events during data moving, merging and processing, and can provide better control and track of the data as it gets transformed and prepared for the new production system.
One crucial step of this process is the mapping between the MST and the different legacy data stores. Each field in each legacy system must be precisely mapped to a corresponding field in the MST, and the mapping has to be carefully documented. Other strongly recommended steps, such as data cleaning and fixing, can also take place in the main stage table. For example, during their analysis, the cheminformatics professionals or other subject matter experts may identify some data points which should not be part of the new system. Those deprecated records can then be marked for deletion in the MST while the data is getting processed, and later those marked records should not be imported in the final, production environment. Similarly, records that have to be fixed or standardized can be modified and the updated data points can also be added to the main stage table as new records.
This way the MST will keep receiving freshly generated data during the whole migration, and the table will hold any data that has been created, updated or marked for deletion. By the time the data cleaning and transformation is finished, the MST is going to hold the final state of the data ready for validation, testing and moving to the production environment.
Validation
When data is moved from its source to another place, it is crucial to perform data validation after the move. The goal of the validation is to ensure data quality and correctness and that no data corruption happened during migration, i.e., that the data remained intact. A proper validation process requires close collaboration between data owners, architects and other - sometimes external - experts to form a consensus about data validation rules with special emphasis on chemical structural data.
As a best practice, all results collected during the validation phase have to be collected in a validation report. Inconsistencies identified in the migration results and documented in the validation report will have to be translated into new tasks where the data will be reviewed, corrected and then validated again.
The actual validation steps may change depending on the data that has to be migrated and the workflows used to create, process and consume it. However, when moving chemical structural data, a mandatory task is to check if each and every structure has been migrated to the new location. This requires a chemical search engine, such as Chemaxon’s JChem cartridge technology and its full fragment search type, which can be used to query every single molecule from the source database against the target database. By making sure that the target location contains the exact same molecules as the source, the validity of the data can be confirmed.
If the migrated data set has some internal hierarchy, for example, it contains parent chemical structures and their batches as well, it is highly recommended to validate that this hierarchical information has been correctly transferred from the source to the target location. The goal of this validation step is to report any change in the data hierarchy caused by moving the data from its original place. To accomplish this task, a script has to iterate through each of the migrated compound batch records and identify their respective parent structure. The number of batches linked to each parent is then compared between the source and target databases, and any discrepancies have to be recorded in the validation report.
Test and Production environments
Following a successful validation, the migrated data is ready for the testing phase, which should include automated testing, as well as user acceptance testing (UAT). Once the curated and transformed data has been loaded, business analysts should perform an in-depth analysis of the new data and create test cases to cover specific functionality along with some end-to-end use cases. These test cases are then translated into automated test scripts, executed one by one, and finally their results are analyzed by a business analyst. It is important to reserve enough time for automated testing, especially since it is an iterative process where any negative test result would require data correction, updating the testing scripts and repeating the test execution from the beginning. In the final iteration there should be no more failing tests, which also means that the user acceptance test can be started.
A UAT team is composed of data owners and end users. End users are often data creators, and they are the ones who know the data the best. During UAT, testers should create test scenarios which will prove the quality of the new data, along with the successful application of the new business rules. Just like with automated testing, any failed test results have to be analyzed by business analysts and the corresponding part of the data has to be fixed and the system has to be prepared for the next UAT cycle. Once the UAT team confirms that there are no more open issues, the testing phase can be closed.
If there is a dedicated test environment or in case of using another solution - such as a Master Stage Table - to transform and fix the migrated data before it can be loaded into the final, production environment, finishing the UAT also marks the point when the data is ready for transition from the test environment to production.

Fantastic! You have just completed the third major step of your migration project. You not only moved your data from the legacy source to its final destination, you also made sure that the project team and key data users tested it and confirmed that the migrated data is ready to be used in production. You are almost ready to close the project; however, to ensure the long term success and seamless adoption of the new system, first you have to take care of some post-migration tasks in the hypercare phase.