
This is the first stage of our Chemical Data Migration best practices whitepaper. Learn how to plan your project and assess your data in Stage 1, make sure your data is clean and compliant with business rules in Stage 2, execute the de facto migration in Stage 3, and ensure adoption and long term success with post-migration validation and support in Stage 4.
Introduction - Why would anyone want to migrate their chemical structure database?
Organizations engaged in Chemistry R&D endeavors will eventually need to migrate their data. The need for the migration may be the result of an acquisition, a change in technology, a database architecture upgrade, or the centralization of data stored across different laboratories/offices. Although it should be apparent that a chemical data migration is not a simple copy and paste task, this process is often underestimated in cost, time, and scope. Many tasks are overlooked at the early stages of project planning, and are only discovered when the issue arises.
This white paper will be of value for the following groups:
|
Role |
Responsibilities |
Example Job Titles |
|
Cheminformatics Professionals |
Provide guidance on and contribute to system configurations and business rules for data curation |
Cheminformatician, Chemical Data Scientist Application Scientist |
|
End Users |
|
Medicinal Chemist Synthetic Chemist CRO Chemist Computational Chemist Analytical Chemist Inventory Manager |
|
IT Professionals |
|
Research IT Product/Resource Owner Database Administrator System Administrator Data Product Manager Data Architect Software Engineer Solution Architect |
|
People/project management |
|
Project Manager Business Analyst Principal Scientist Directors Executives |
Data migrations are something most people hope to simply survive. We hope this white paper will help you not only to do that, but also succeed.
A framework for a successful chemical data migration project
Process Outline
The most significant hurdle organizations run into when planning a chemical database migration is failing to understand that the migration itself is but a small part of the overall process. The success of the project relies highly on proper project planning and data assessment from an organizational, chemical, and business needs perspective. In order to properly understand the complexity of this process, the workflow will be broken up into four stages:
Each stage will address what needs to be considered for the given step, as well as common issues that may arise and for which a preventive or corrective measure will be suggested.
Stage 1: Project Planning and Data Assessment
In the initial planning phase, it is important to consider all the various tasks required to properly perform a chemical data migration. The order in which tasks should be performed, as well as who will be assigned to each task, should be determined early in the process. Additionally, decision makers should be determined for each task to avoid confusion and delays in the implementation process. Lastly, metrics for success should be defined so the team can evaluate if a stage can be considered complete and the project ready to progress to the next stage.
Understanding the underlying data in conjunction with the organization's operational business needs is a fundamental step in the overall process and should be the preliminary focus.
A team should be set up to address the following topics:
- Project management
- Development of business rules
- Data architecture
- Chemical data analysis
It should be noted that these tasks are not separable from each other and do not necessarily have a fixed order. Discoveries and decisions made in each section will impact the other ones.It is important to note that each chemical database migration project is unique, and to elaborate on the variable scenarios would be too exhaustive for the purpose of this paper. As such, we treat each task individually and discuss overlap with other tasks where appropriate.
Last, but not least, we would like to emphasize that chemical database management should be an ongoing process in an organization. We recommend that organizations have a data product manager or at least a process to maintain the integrity of the chemical data. Additionally, there are many tools available to help maintain chemical integrity and automate data processing, such as structure checkers, standardizers and database cartridges. Implementing such processes and tools, as well as training data creators and consumers on their usage have a huge advantage and enable significant cost savings in a future data migration project.
Project management
Managing a chemical data migration can be challenging as the process requires cooperation among team members specializing in significantly distinct disciplines. Ideally, this endeavor will be led by a project manager with a background in chemistry, who can understand chemically related issues as they arise and guide the team to proper resolutions. An iterative project management approach (e.g., Agile) should be implemented in the planning and data assessment phase, as the three main tasks during this phase - development of business rules, data architecture, and chemical data analysis - are interdependent. For instance, business rules will impact how structures are to be standardized; however, analysis of the chemical data may guide the development of new and/or modification of existing business rules.
Lastly, prudent planning will include a contingency for some data curation post-migration. As such, it is important to define a success metric when setting project goals.
Development of business rules
Business rules are typically defined and documented by a business analyst. Since it is not common for a business analyst to have a background in chemistry, communication with management, IT and other team members is crucial for properly defining the business rules.
- Rules for access control: From the perspective of data management, the creation of project groups and user groups in conjunction with overall security/data access is important to define and document. This includes determining read, write and edit privileges for these groups for the different objects in the database.
- Rules for what gets stored: One of the first questions to decide is about what kind of entities will be stored in the database. Besides individual small molecules, are other chemical or even biological entities also registered in the same system? Some of these structure types, such as formulations, mixtures, (bio-)polymers or antibody-drug conjugates necessitate an additional level of complexity - the details of which are out-of-scope for this whitepaper. However, as the best course of action, such multi-component substances can be described as a combination of single-component compounds, which are also present in the data set. These business rules also have to define every additional data field for the different entities. For each field, it has to be documented if it is mandatory or optional, if values are generated automatically or inserted manually and if there are any validation rules.
Additionally, there may exist records where the structure should be hidden in the database for security reasons. Whether or not those records should be generated as “NoStructures” should be considered, as well as what mandatory fields are necessary for record keeping.
Another decision to be made is whether an organization wants to store information about the batches, i.e., the submitted samples of a substance in the same database.
- Structure representation rules: A chemical structure can be represented in several different ways, which affects not only the graphical layout of the molecules, but it might have a more fundamental effect on topology making compound identification and duplicate checking more difficult. Aside from basic chemical drawing rules (e.g., Are abbreviated groups allowed? How should aromatic rings be represented?), there are more complicated scenarios to address:
- Recording counterions and solvents, as well as their multiplicity is necessary to keep track of different salt forms and solvates of a compound. However, these can have significant variance in their representation, so it is best to have rules which clearly define if counterions and solvents should be drawn as part of the structure and/or be a separate field in a table, if they will be drawn neutral or as acid/base pairs, how will the stoichiometry be represented, and whether or not two identical parent structures with distinct salt or solvate modifiers are given different compound identifiers.
- Stereochemical features including the configuration of chiral centers, E/Z isomers and atropisomers are key characteristics of molecules in the pharma industry and they play an important role when searching for duplicate molecules. Our recommendation is to use the industry best practice enhanced stereochemistry notation to define chiral centers with resolved or unknown, absolute or relative configurations, as well as mixtures of multiple stereoisomers. It is important to have a document defining drawing rules as they relate to ambiguous scenarios. For example, if a structure has a single stereogenic center drawn with a flat bond, does this mean the chirality is unknown, or is this a mixture? The answer may seem obvious; however, more complicated and potentially ambiguous scenarios for enantiomeric mixtures, diastereomers, etc. should have drawing rules defined for standardization. Another best practice is to include an additional text field for stereochemistry comments in the database to ensure that stereochemical features are defined unambiguously for each molecule. Such stereo comments can help settle any controversial questions, and they can also serve as reference in any future migration project.
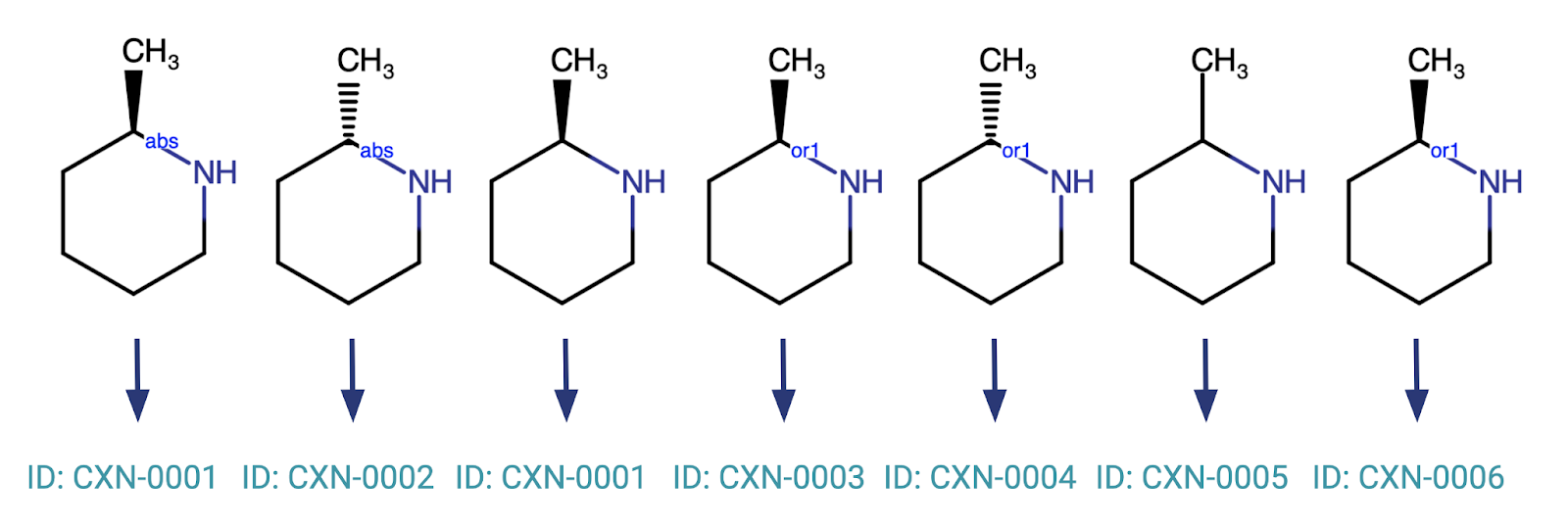
- There are several chemical functional groups which can be drawn and represented in multiple ways, such as the nitro, nitroso or the sulfoxide group. Standardizing these differing, but chemically equivalent, representations reduces the risk of missing duplicates during structure searching or new structure registration.
Data architecture
When creating the data architecture, some important things to consider are the hierarchy of chemical samples and their identifiers, the handling of legacy identifiers, and which fields should have a controlled vocabulary. A business analyst will typically convey the business rules surrounding these areas to a data architect or some other members of the informatics group, who will then design the database to take in the data in the prescribed manner.
- Many organizations store chemical structures in a multi-level hierarchy. An important task is defining how many levels will be used, what these levels are called, what the identifiers are at each level, and how legacy structure data will be mapped into this hierarchy. At the top of this hierarchy is a “parent” structure, which represents the structure without any salts or solvates. The next level contains the specific chemical entity (or “version”) being stored - including salts and solvates. For example, the three entities benzylamine (neat), benzylamine hydrochloride, and benzylamine monohydrate would all have the same parent ID (since the parent structure is benzylamine for all of them), but would each have a distinct entity ID. A further level (“batch” or “lot”, etc.) can be added to store information about each submitted sample of a substance, such as notebook reference, purity, etc. Some organizations omit the “version” level and have a direct batch-parent relationship.
- In scenarios where a data migration includes the merging of two or more databases, it is possible that there are distinct identifiers for compounds, batches, lots, etc. This is particularly common when a company has made one or more acquisitions. In cases like this, it is highly recommended to preserve the legacy identifiers and store them as aliases to the identifiers as it can contribute significantly to business continuity.
Merging multiple data sources could also mean that some legacy fields may not precisely map to the new schema. In such a situation, preserving a carefully selected subset of these fields may be desirable for business continuity and data integrity. - There are certain data fields that are beneficial to have represented in a standardized and restricted form. Data dictionaries can be created for these fields, in order to have a controlled and consistent vocabulary. Typical examples include a salt/solvate dictionary, suppliers and vendors, and structure related terms. For salts and solvates, having a dictionary is a good way to enforce representation as an acid or base, restrict certain salts, and enforce the use of certain names when a salt may have more than one. From a chemistry perspective, the best course of action is to use and store the structural representation of counterions and solvents instead of storing them as text labels. This way chemists can add them while they are drawing their molecules, and then the dictionary can be used to strip them when only the parent structure itself is needed.
To prevent tracking issues, having a dictionary for suppliers and vendors is useful as it prevents multiple representations of the same company. Lastly, in the event that a drawn structure is not enough to represent uniqueness or when the structure is only partially known, an additional field may be used to ensure a compound is in fact unique. An example of this is a pair of separated enantiomers for which the absolute stereochemistry is not known. A possible method to handle this situation is to have a field that names one “Isomer #1” and the other “Isomer #2”.
Chemical data analysis
The data analysis will focus primarily on understanding the data from a chemical perspective. The majority of the work will be performed by a cheminformatician or someone with a similar skillset, and the analysis will be guided and reviewed primarily by the end users. We break up the analysis into four main goals:
- Identify the level of chemical complexity in the current database and the desired level of complexity in the future state: Chemical complexity refers to the level of detail in which structures are represented, taking into account advanced stereochemistry, tautomerism, atropisomerism, and file format. To have a structure representation which can properly describe all the necessary details, you need to use a format that supports a wide range of chemical features. On top of that, this format needs to be recognizable by other systems. The MDL MOL V3000 format meets these requirements and is the de facto industry standard for storing chemical structures; however, it is still quite common that organizations use the legacy V2000 version, where support for enhanced stereochemistry is missing. SMILES is another popular format, especially to exchange information with external partners. It has, however, only limited stereochemistry support and does not store any atomic coordinates.
In regards to advanced stereochemistry, tautomerism, and atropisomerism, what needs to be considered is:
- Whether that particular level of sophistication will be captured and how.
- How the current chemical library will be standardized to represent the given level of sophistication.
- How future registrations will be performed to maintain the defined standardization rules. Some decisions for the future state are easily backward compatible, and the current database can be cleaned for that particular scenario. Tautomers are an excellent example of this. A more complicated example would be a V2000 structure where the advanced stereochemistry is captured in a comment field.
While it is possible to set up extra data fields to support different kinds of chemical structure related properties such as stereochemical information, it is considered a best practice to incorporate as many chemical details in the structures themselves as possible. Although defining a sufficiently detailed structure representation might look like a very complex task, it is well worth the effort since it makes data standardization and uniqueness checking much more straightforward. Consider, for example, that you only have to compare values in one field to identify duplicates, and you do not have to maintain additional data fields with standardized values, validation rules, underlying dictionaries and so on. It is worth mentioning that there are some cases where a pair of molecules cannot be compared based on their chemical structure only (e.g., when you have a pair of unknown stereoisomers). In such a situation, you cannot avoid using an additional data field or some attached data values even if you use a very detailed structure representation. It is recommended that such fields be kept to a minimum, with a carefully controlled set of allowed values.
- Define what makes a record/structure unique: The more sophisticated the way in which structures are represented, the easier it is to define their uniqueness. For example, if tautomers are not standardized, will the system recognize a pair of tautomers as two distinct structures, each with their own identifier, or will they be considered the same structure? Adding complexity can be challenging, but it helps mitigate these scenarios.
When you define the rules of uniqueness, you cannot forget about those “chemistry heavy” features, which were mentioned in the previous sections. In other words, you have to consider how you want to track the different salt forms, solvates, stereoisomers, tautomers and isotopologues of a compound. Do you want to keep different forms as separate entities with different compound identifiers, or would you rather represent them with a single chemical structure and a single compound ID while creating a new lot for each new form under the corresponding representative compound.?
- Identify and classify the errors that exist in the database: After the rules for structural and record uniqueness have been defined, the integrity of the chemical data can be analyzed. While assessing the data, there are some common issues that should be looked for. Some of these errors, such as inappropriate bond lengths and bond angles, affect only the layout of the molecules. Other error types may affect the chemical interpretation of a structure, such as incomplete or ambiguous stereochemical information.
- Duplicate structures that have different compound identifiers: This typically happens when the system fails to identify that a registered structure already exists in the system. Then a new parent identifier is created, instead of associating the submitted sample with an existing ID.

- Different structures sharing the same compound identifier: This scenario typically happens with stereoisomers that appear the same, but are not. Complications arise when stereoisomers are not properly drawn and the intention of the chemist must be determined.

- Intersystem duplicates: These are duplicates of the above two scenarios which exist across databases. An example could be an organization that has separate offices using distinct databases, or when an acquired company has some chemical library overlap with the parent company.
- Invalid chemical structures: Examples include structures that violate an allowed valence on an atom. These scenarios are rare as many drawing programs will alert a user; however, mistakes do happen. A structure checker embedded into a registration tool will prevent these issues for new registrations; while, legacy structures may have been entered without the benefit of such checks.

- Structures that are drawn correctly, but are not the intended structure: These are almost impossible to identify programmatically and are usually caught when they are part of a duplicate scenario.
- Business rule errors: These are structures that are technically correct, but they violate the rules of an organization. Good examples of this would be a covalently bound counterion or a functional group represented by an abbreviated group in an organization that does not allow abbreviated group representations. Appropriate structure standardization can avoid many of these problems.

By the time you complete Stage 1, you will be in a position where you have a properly planned data migration project ahead of you. You have decided who will participate in the project, who are the decision makers, how the project team will work, and how they will measure the project success. As part of the planning process, the team has defined rules for access control, decided what kind of data will be collected and how the whole data set will be structured to ensure data integrity and business continuity. By analyzing the existing data from a chemistry point of view, you have a clear definition of the data you need to unambiguously describe and distinguish chemical structures, while you also collected information about the different error types present in the data.
Thanks to this planning and analysis, you successfully set the foundation for Stage 2, and are now ready to start the curation of the legacy data to ensure its consistency and to make it compliant with the latest business rules. Click here to read our post on Data Curation.