
This is Stage 2 of our Chemical Data Migration best practices whitepaper. Learn how to plan your project and assess your data in Stage 1, make sure your data is clean and compliant with business rules in Stage 2, execute the de facto migration in Stage 3, and ensure adoption and long term success with post-migration validation and support in Stage 4.
In the previous stage, you worked on the planning of your data migration project, defined business rules about what kind of data will be stored and how it will be organized, as well as analyzed your chemical data to define how molecular structures will be represented and distinguished or what kind of errors are present in the existing records.
After all this preparation, you are now ready for Stage 2, the curation of the legacy data. The primary goal of this phase is to make existing data - chemical structures along with their additional data - compliant with the latest business rules by transforming, cleaning and standardizing the records, removing any duplicates and fixing structural and other errors.
The primary goal of data curation is to ensure consistency over the entire legacy data set including chemical and non-chemical data. Consistency, in this case, is defined by the rules that were born from the assessment done in the previous phase. In other words, the data curation phase is where we transform legacy chemical structures, as well as their additional properties to
- Describe molecules with the appropriate level of complexity,
- Clean and standardize existing records to harmonize the representation of chemical structures and the nomenclature of non-chemical data,
- Identify and fix any drawing related or other errors in the legacy data,
- Filter out duplicates based on predefined uniqueness rules and merge duplicate records when it is necessary.
In practice, data curation involves mostly data cleaning and merging steps. There is a wide variety of curation software and pipelines that can be used to transform non-chemical data; chemical structure data, however, requires special treatment and some specialized tools as well. Software that can convert between a variety of chemical formats, recognize stereoisomers and tautomers, normalize chemical structures, as well as identify and fix structural errors is a must to successfully curate any chemical data set. While the actual steps and rules may differ at every organization, a chemical data curation workflow always has to consider the following:
- Describing structures with the appropriate level of complexity:
- Format conversion: As part of the data curation, all legacy compounds have to be converted to the same format, preferably MOL V3000, and then these converted structures have to be used as input in further data cleaning and merging steps.
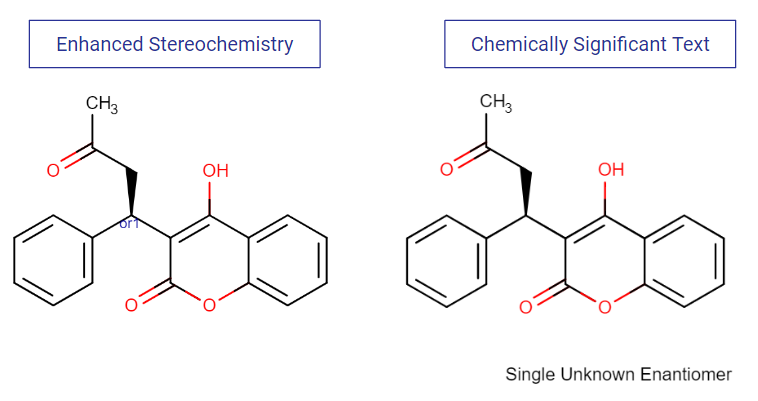
- Stereochemistry: Although the enhanced stereo representation has been available for a long time and has become an industry standard, it is still not unusual to store stereo information in text fields as stereo comments or to use attached data to associate stereo features with chiral centers, bonds or entire molecules. These legacy solutions can be a problem, as most of the time they are not easily transferred to the new system, and the affected structures require extra standardization during migration.
A data curation best practice would be to identify all the different stereo notations used in the legacy system and map them to standard, structure-based stereochemical features including chemical bond types and enhanced stereo labels. Once the mapping is complete, automated structure standardization tools can be used to replace legacy notations with standard stereochemical features.
- Salts and solvates: Information about counterions and solvents, their chemical representation and multiplicity can exist in several forms in different databases. Such differences can make it very difficult to identify duplicate records, so each data curation project has to make sure that different descriptions get converted to a single, uniform representation.
If in the legacy data counterions and solvents were drawn as part of the molecule’s structure, then these fragments have to be detached and stored separately from the main molecule to enable the tracking of the different salt forms and solvates of a molecule. In case of a text-based salt/solvate representation, text labels have to be converted to the corresponding chemical structure. Finally, legacy salt and solvate modifiers have to be mapped and replaced with the appropriate item of the salt-solvate dictionary, which was created in the Data Assessment stage.
- Isotopologues: To distinguish isotopic variations of a molecule, the best practice is to add all isotope-related information to the chemical structure itself. Then the outcome of the data assessment and the new business rules have to be used to decide how isotopologues should be organized and stored in the new system.
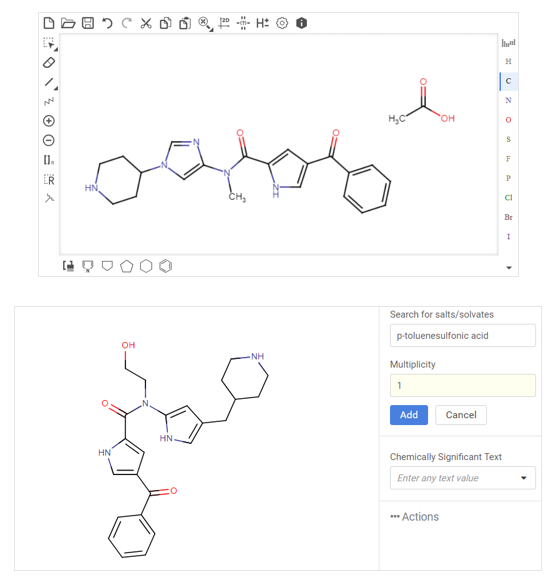
- Compounds with an unknown or partially known structure: Legacy data sets often contain molecules where the chemical structure is not known or is not defined completely. Before migrating such molecules, it is important to check what kind of other information has been used to describe those compounds, for instance, if any text- or image-based description is available. Migrating static structure images usually requires re-drawing the molecules. In this case, optical structure recognition (OSR) software can help automate the process to some extent; however, the automatically recognized structures still require a review by an experienced user. Text-based descriptions on the other hand can be converted to standardized chemically-significant text using a controlled vocabulary and replacing free text descriptions with vocabulary-based terms.
- Structure cleaning and standardization: A chemical structure existing in multiple different representations in a database can happen quite often in data sets where compounds come from several different sources or where molecules are drawn by people with different chemical drawing habits. The main objective of structure standardization is to transform chemical structures into a uniform, canonical representation in order to avoid structure duplications and differences in the graphical appearance of molecules.
Typical standardization includes the removal of explicitly drawn hydrogen atoms, the dearomatization molecules, as well as neutralization and salt stripping as mentioned in the previous sections. Different tautomeric forms (e.g., generating the canonical or dominant tautomer of a molecule) and functional groups where multiple chemically valid and equal representations are possible can also be handled with the appropriate standardization steps.
Using the same automated structure standardization workflow during data curation as well as when you add new molecules after the migration can make sure that all of your compounds will be represented the same way. However, in order to further increase the quality of your data, it is recommended to set up internal drawing conventions and to train users to use them. In addition, make sure that you have documentation with the details of those conventions, as well as in-house experts who are familiar with them, their usage and the reason why they are there.

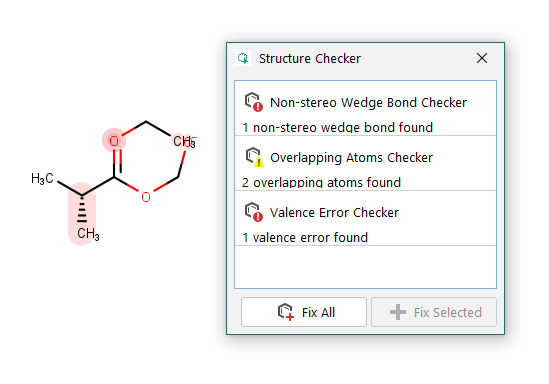
- Identifying and fixing structural errors: Chemical data sets may contain any number of structural errors related to drawing mistakes, failed format conversions or some other issues. If such errors are present in the legacy data set, it is crucial to identify and fix them before migrating the data to the new system. Some of these errors can be fixed automatically; for example, covalently bound counterions can be removed from the structure and added as a salt modifier instead. Other error types, such as valence errors have to be fixed manually.
While automated structure checking and partially automated structure fixing can make error handling faster and more accurate, combining them with internal drawing guidelines and properly trained in-house power users - as suggested in the previous bullet point - enables even higher data quality with the least amount of manual work.
- Managing duplicates: Removing or merging duplicate entries is part of every data curation project. How duplicates are defined depends on an organization’s business rules and determines which attributes must be checked when looking for matching entries. In the case of molecules, for example, you have to search for matching chemically-significant text as well besides identifying matching chemical structures.
In regard to cleaning the data and resolving duplicate issues, order is important. It is best to clean and standardize the erroneous structures first then identify all molecules that are considered duplicates under the new business rules. As a next step, you have to decide how to handle those duplicates: determine which duplicate of a pair gets reassigned and which retains the current identifier. This is an example where the end users who have been instrumental in identifying these duplicates will need to collaborate with the business analyst, a cheminformatics expert and the data architect. The business analyst may have an understanding of the prioritization order, while the cheminformatics expert and the data architect would be helpful in identifying those features. Furthermore, an issue may be found during duplicate resolution that the business analyst did not consider. For this reason, the cycle will often need to be iterated one or more times.
If the duplication was a result of an error, you have to find the correct entry and remove the erroneous ones. If you have to merge two different salt forms of the same molecule, you have to check how the other, additional data values of the merged molecules have to be modified and what should happen with their identifiers. In case they had two different corporate IDs, you decide if you want to keep one of the IDs or if you want to generate new IDs for each matching molecule and store the old ones in a separate data field dedicated to collect legacy IDs and aliases.
It might happen that a data set contains multiple different molecules with the same corporate identifier because of some mistake or because your new business logic dictates that you have to handle stereoisomers or tautomers as separate entries. In a case like this, you have to generate new IDs for the affected molecules (or let one of them keep the original ID and generate new ones for the other molecules), and add the old, repeated IDs to an alias field. In order to resolve these problems, it is crucial to establish a “source of truth” as part of the migration plan.
Migrating your legacy data to a new system without deduplicating it according to the latest business rules may lead to problems with structure matching once you start adding new molecules as well. Besides, changing the duplicate handling rules after the migration has been completed may lead to inconsistencies in the data which can be fixed only by repeating the whole migration process.
Congratulations! By this time you have transformed your legacy data to a format that is compatible with your latest business logic. You standardized chemical structures and other data fields where you have to control the possible values, removed duplicate records and fixed several other chemical and other errors in your data. You are now ready for the next step, to actually move the legacy data from the original data source to the new one.